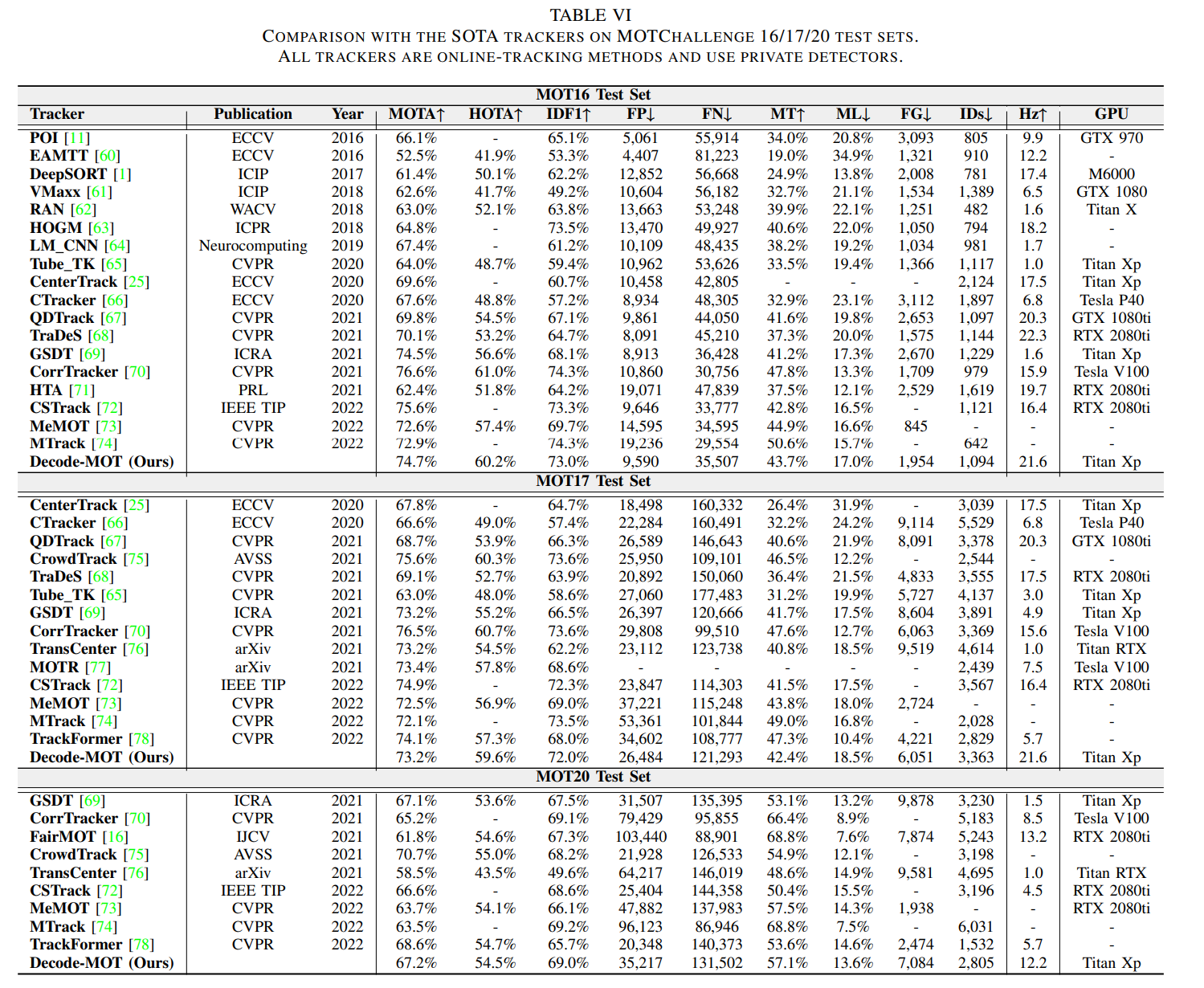
Fig 1. Accuracy and speed of the recent methods on the MOTChallenge dataset.
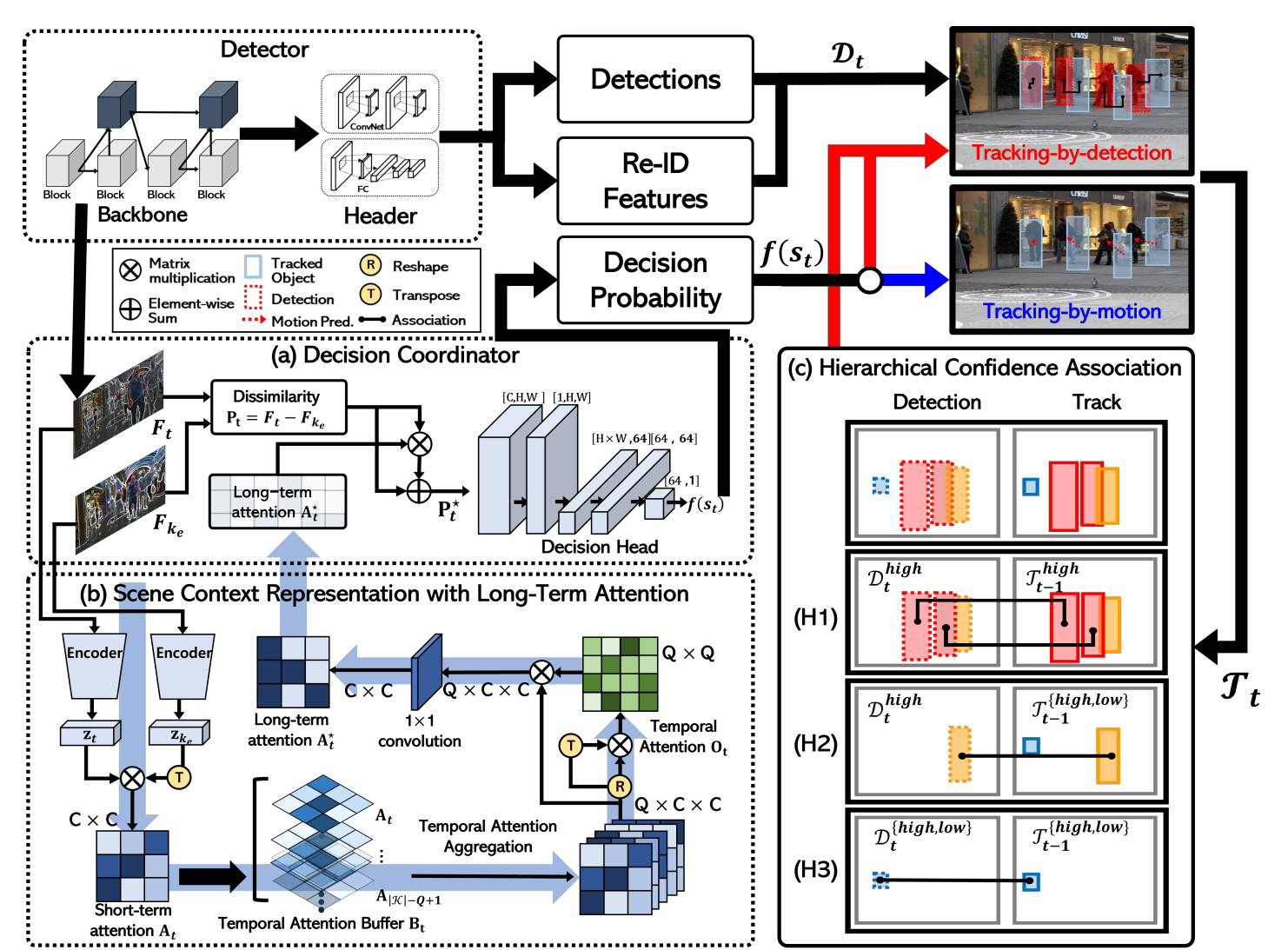
Fig 2. The overall architecture of our Decode-MOT. It consists of (a) a decision coordinator of predicting the probability of TBM, (b) a scene context representation module of evaluating
the long-term attention between different frames, and (c) a hierarchical association of linking between detections and
tracks progressively
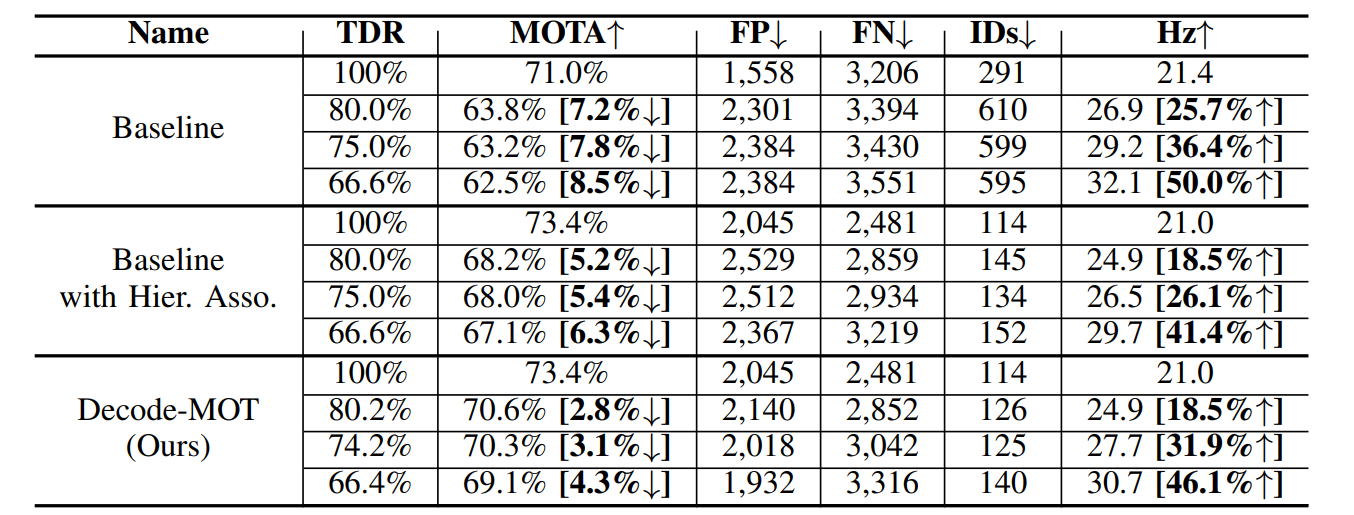
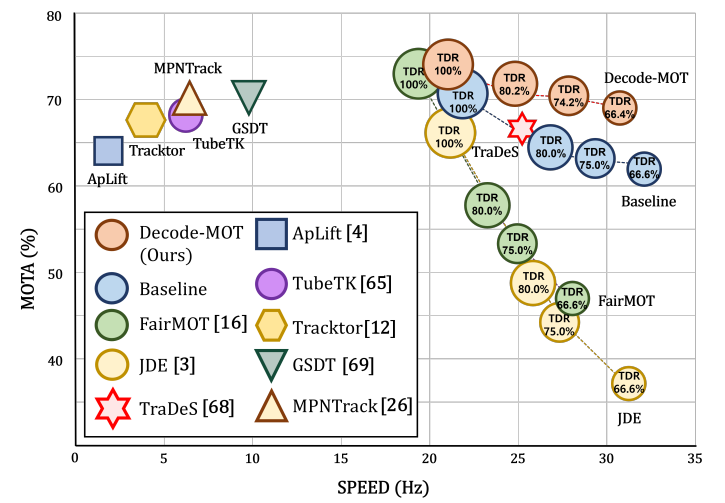
COMPARISON AMONG OUR DECODE-MOT, THE BASELINE WITH THE HIERARCHICAL ASSOCIATION,
AND THE BASELINE TRACKER WITH DIFFERENT TDRS ON MOT15 DATASET.
THE PERCENTAGE IN [·] SHOWS THE SPEED GAIN AND ACCURACY REDUCTION RATES OF EACH TRACKER AS TDR DECREASES